BCEM 393 Lecture Notes - Lecture 17: Hypoxanthine, Peptidyl Transferase, Hydrolysis

28 Jun 2018
School
Department
Course
Professor

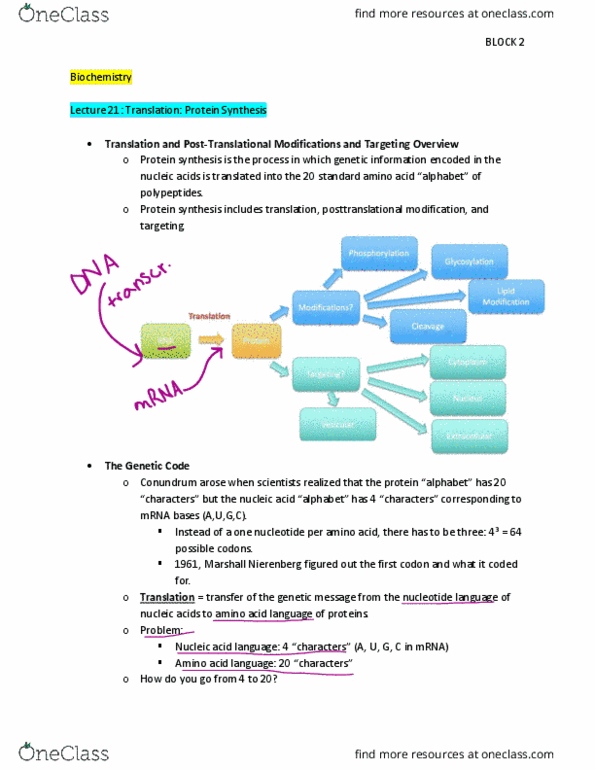
Genetic Code and Protein Translation
TRANSLATION
-mRNA is the only type of RNA that is translated into proteins
-The four letter alphabet of nucleic acids GCAU is translated into the entirely different 20 letter
alphabet of proteins (20 amino acids)
-The genetic code refers to the relation between the sequence of bases in DNA (or its RNA
transcripts) and the sequence of amino acids in proteins
-Prokaryotes: ribosomes can start translated mRNA during transcription
-Eukaryotes: mRNA is processed an transported outside the nucleus before translation can
start in the cytoplasm
-Because 4 nucleotides, taken individually, could represent only 4 of the 20 possible amino
acids in coding the linear arrangement in proteins, a group of three nucleotides is required to
represent each amino acid
-4 possibilities in each slot of the 3-nucleotide codon
-4^3 = 64 possible codons code for 20 amino acids —> The Genetic Code
GENETIC CODE
-1. The set of rules used by living cells to translate information encoded within genetic material
into proteins
-2. Three nucleotides (= codon) encode an amino acid
-3. The code is non overlapping
-ABCDEF —> ABC DEF
-ABCDEF —> ABC BCD CDE DEF X (not possbile)
-4. The sequence of bases is read sequentially from a fixed starting point (= AUG, Met) without
punctuation (no halts) to an end point (1 of 3 Stop Codons)
-5. The genetic code has directionality — Read 5’ —> 3’
-6. The genetic code is degenerate:
-64 possible base triplets (61, excluding STOP codons) and only 20 amino acids
-Degeneracy in genetic code reduces the change that mutations change the protein made
-Synonymous (silent) mutations vs. nonsense mutations
-Often times, Met is later removed before the protein functions in the cell
-Only Met and Trp (tryptophan) are encoded by just one codon
THE GENETIC CODE IS (NEARLY) UNIVERSAL
-This accounts for the fact that human proteins, such as insulin, can be synthesized in the
bacterium E. coli and harvested from it for the treatment of diabetes
ACCURATE RECOGNITION OF CODONS — TRNA FUNCTION
-An amino acid itself is not structurally complex enough to recognize a codon
-tRNA serves as the adapter molecule between the codon and its specific amino acid
-tRNA Structure:
-Approximately half the nucleotides in tRNAs base-paired to form double helices
-Five groups of bases are not base-paired in this way:
-The 3’ CCA terminal region — acceptor stem (amino acid attachment site)
find more resources at oneclass.com
find more resources at oneclass.com

-The TpsiC loop, named from the sequence ribothymine-pseudouracil-cytosine
-This loop is a specialized region which acts as a special recognition site for the ribo-
some to form a tRNA-ribosome complex during translation
-The “extra arm” — contains a variable number of residues
-The DHU loop — contains several di-
hydrouracil residues
-Believed to act as a recognition
site for aminoacyl-tRNA syn-
thetase, an enzyme involved in the
aminoacylation of the tRNA mole-
cule
-Anticodon loop — interacts with
mRNA codons via Watson-Crick base
pairs and Wobble base pairing
WOBBLE BASE PAIRING
-If Watson-Crick Base Pairing were exclusively responsible for codon-anticodon interactions,
then an anticodon can recognize only one codon
-Cells have less than 64 tRNAs specific for a certain codon because of wobbkle base pairing
-Maximum 41 tRNAs present
WOBBLE BASE PAIRING HYPOTHESIS
-The first two bases of an mRNA codon (read 5’ —> 3’) always form strong Watson-Crick base
pairs with the corresponding bases (3rd and 2nd position) of the tRNA anticodon
-The first base of the anticodon (reading in the 5’ —> 3’ direction; this pairs with the third base
of the codon) determines the number of codons recognized by the tRNA
-When the first base of the anticodon is C or A, base pairing is specific and follows Watson-
Crick base pairing —> only one codon is recognized by that tRNA
-When the first base is U or G, two different codons may be read
-When hypoxanthine (I) is the first (wobble) base, three different codons can be recognized
-This hypothesis explains why multiple codons can code for a single amino acid
-Wobble Base Pairing at 1st Position in the Anticodon
-Degeneracy of genetic code arises from non-specific base pairing at first nucleotide in the
anticodon with 3rd nucleotide in codon
-Does not follow normal base pairing
TRNA LOADING
-Before codon and anticodon meet, the amino acids must first be loaded onto a specific tRNA
molecule
-Establishes a genetic code
-Activates (charges) the amino acid because formation of a peptide bond between free
amino acids is thermodynamically unfavourable —> thus first form an amino acid ester with
the 3’ end of the tRNA
TRNA LOADING — TRNA SYNTHETASE
-Attachment of the appropriate amino acid to a tRNA, is catalyzed by a specific aminoacyl-tR-
NA synthetase
find more resources at oneclass.com
find more resources at oneclass.com
Document Summary
Mrna is the only type of rna that is translated into proteins. The four letter alphabet of nucleic acids gcau is translated into the entirely different 20 letter alphabet of proteins (20 amino acids) The genetic code refers to the relation between the sequence of bases in dna (or its rna transcripts) and the sequence of amino acids in proteins. Prokaryotes: ribosomes can start translated mrna during transcription. Eukaryotes: mrna is processed an transported outside the nucleus before translation can start in the cytoplasm. Because 4 nucleotides, taken individually, could represent only 4 of the 20 possible amino acids in coding the linear arrangement in proteins, a group of three nucleotides is required to represent each amino acid. 4 possibilities in each slot of the 3-nucleotide codon. 4^3 = 64 possible codons code for 20 amino acids > the genetic code. The set of rules used by living cells to translate information encoded within genetic material into proteins.