PSY1022 Lecture Notes - Lecture 11: Standard Deviation, Squared Deviations From The Mean, Frequency Distribution

26 May 2018
School
Department
Course
Professor

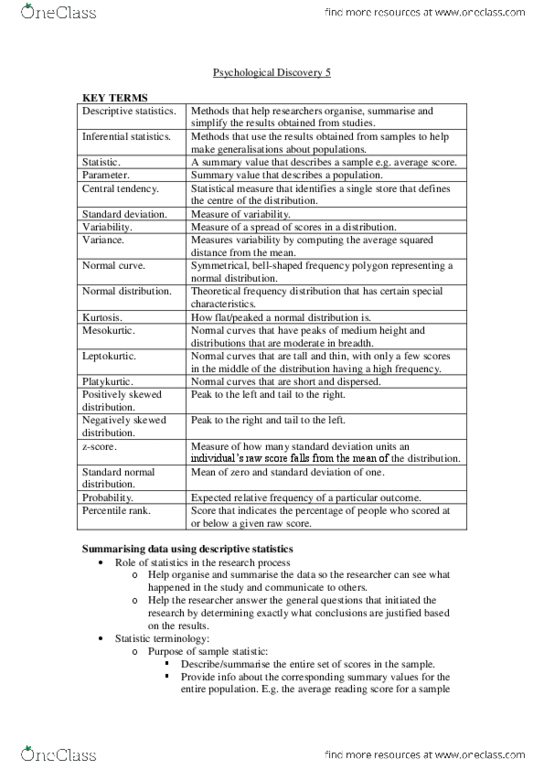
PSY1022 – Lecture – Week 11 – Summarising data using descriptive statistics
- descriptive statistics entail the organisation, summarisation and simplification
of raw data so that patterns and trends in variables can be seen
- a descriptive value for a population is called a parameter - symbolised by greek
letters and a descriptive value for a sample is called a statistics symbolised by
regular letters
- inferential statistics - methods for using sample data to make general
conclusions - inferences about populations
• same statistics are used as the basis for drawing conclusions about
population parameters
- frequency distributions
• specifies the frequency of occurrence of each possible score - the number
of times each score occurred on the scale measurement
• can organise and summaries using tabular or graphical techniques
• frequency table - organised tabulation showing how many individual are
located in each category on the scale of measurement
•
o consists of at least two columns - one listing categories on the scale
measurement and another for frequency
o the sum of the frequencies should equal number of participants
• a frequency distribution present an organised picture of the entire set of
scores and it shows where each individual is located relative to others in
the distribution
•
o grouped frequency distributions
o
▪ when a frequency distribution table lists all of the
individual categories - x values - it is called a regular
frequency distribution table
▪ sometimes however a set of scores covers a wide range of
values - in these situations a list of all the x values would be
too long
▪
▪ to remedy this situation and grouped frequency
distribution table is used
▪ in a grouped table the x column lists groups of scores called
class intervals rather than individual values
▪ these intervals all have the same width -
▪ each interval begins with a value that is a multiple of the
interval width
- histograms
• grouped into intervals in a graphical format
• a bar is centred above each score - or class interval so that the height of
the bar corresponds to the frequency and the width extends to the real
limits so that adjacent bards touch
• in a polygon a dot is centred about each score so that the height of the dot
corresponds to the frequency, the dots are then connected by straight
lines an additional line is drawn at each end to bring the graph back to a
zero frequency
find more resources at oneclass.com
find more resources at oneclass.com

• works well for numbers
- bar graphs
• when the score categories - x values are measurements from a nominal or
an ordinal scale the graph should be a bar graph
• a bar graph is just like a histogram except that gaps or spaces are left
between adjacent bars because the data is discrete and separate rather
than continuous
- smooth curve
• if the scores in the population are measured on an interval or ratio scale,
you may present the distribution as a smooth curve rather than a jagged
histogram or polygon
• the smooth curve emphasises the fact that distribution is not showing the
exact frequency for each category
• continuous data
- benefits
• frequency distribution graphs are useful because they show the entire set
of scores
• you can determine at a glance the highest score, the lowest score, and
where the scores are centred
• the graph also shows whether the scores are clustered together or
scattered over a wide range
• variability and spread
• frequency distributions tell us about
•
o shape of distribution - symmetrical or skewed
o central tendency - where do most scores fall
o variability - what is the spread of scores
- properties of distributions
• a graph shows the shape of the distribution
• a distribution is symmetrical if the left side of the graph is roughly a
mirror image of the right side
• distributions are skewed when scores pile up on one side of the
distribution, leaving a tail of a few extreme values on the other side
•
o positively skewed distribution - scores tend to pile up on the left
side of the distribution with the tail tapering off to the right
o negatively skewed distribution the scores tend to pile up on the
right side and the tail points to the left
- central tendency and variability
• central tendency measures the centre of a distribution
• variability measures the spread of distribution
• the goal of central tendency is to identify the single value that is the best
representative for the entire set of data - e.g. the average value
•
o by identifying the average score - central tendency allows
researchers allows researchers to summarise or condense a large
set of data into a single value
find more resources at oneclass.com
find more resources at oneclass.com